My Life &
My Work


To implement Spell Checker using Hunspell library
We need to have a concrete understanding about character conversions among Windows codepage encoding, UCS2 (or UTF16) encoding, UTF8 encoding. If you have a solid understanding of the following concepts, character conversions among the varieties of encodings become much more manageable.
- In the Multibyte encoding system, a single character is represented with one or more bytes. In this encoding system, some characters are represented with a single byte (char) and other characters are represented with two or more bytes (or two or more chars).
Windows codepage encoding is of the multibyte encoding system.
UTF7, UTF8 encoding is of the multibyte encoding system.
std::string is used to represent multibyte character strings.
const char* is used to represent the multibyte C strings.
- In the Wide Character encoding system, each and every character is represented with a single wide character (wchar_t) whose byte size is two bytes.
UCS2 and UTF-16 encodings are of the wide character encoding system.
std::wstring is used to represent the wide character strings.
const wchar_t* is used to represent the wide character C strings.
- To convert Multibyte strings such as codepage strings or UTF8 strings to the Wide Character strings such as UCS2, we use MultiByteToWideChar function.
If we want to convert Windows codepage or UTF8 to UCS2 or UTF16, we have to use MultiByteToWideChar function, because Windows codepage or UTF8 is in Multibyte encoding and UCS2 is in Wide Character encoding.
IMPORTANT: Because both Windows codepage strings and UTF8 strings are of the Multibyte encoding system, we CANNOT convert Windows codepage strings to UTF8 strings with MultiByteToWideChar function. We first convert codepage to UCS2, then convert UCS2 to UTF8. In the same manner, if we want to convert UTF8 to Windows codepage, we have to convert UTF8 to UCS2, then convert this UCS2 to the codepage.
- To convert Wide Character strings such as UCS2 or UTF16 to Multibyte strings such as codepage strings or UTF8 strings, we use WideCharToMultiByte function.
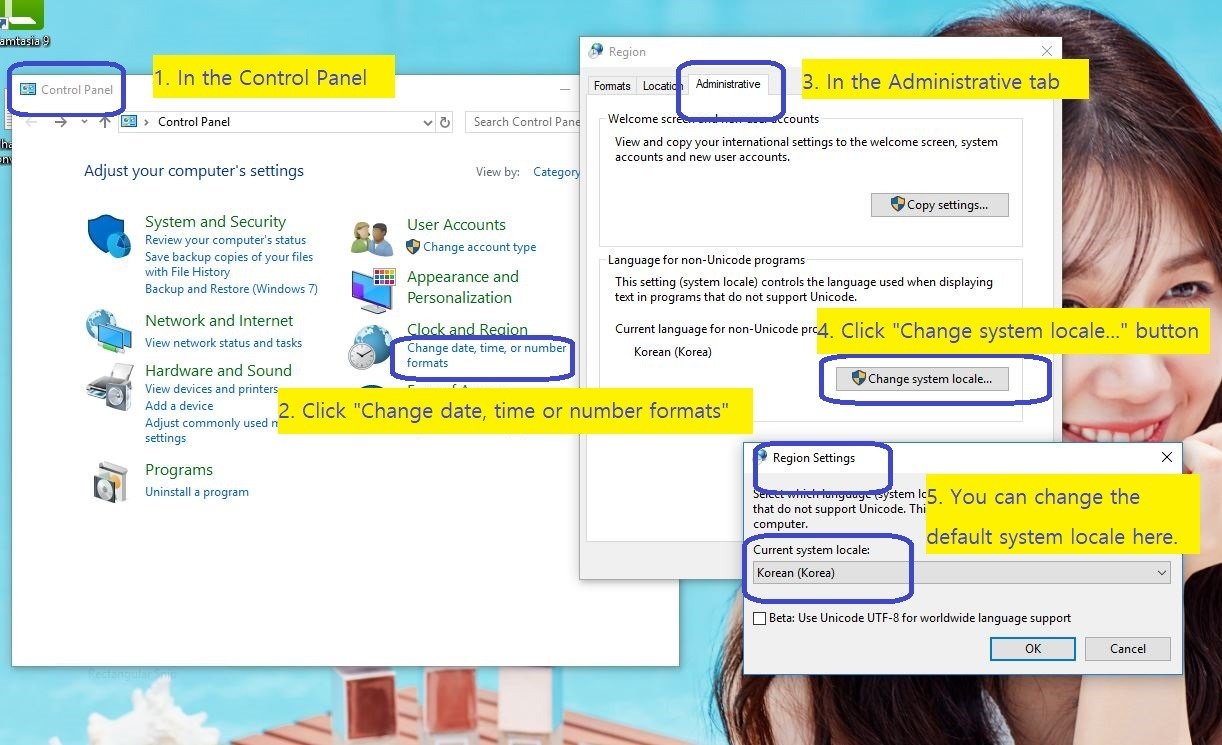
- Another very important concept is System Locale. Each Windows computer has its default System Locale which determines the default codepage.
6. When we use MultiByteToWideChar and WideCharToMultiByte functions to convert to and from Windows codepage, we have to set the default locale to our process (or thread). First, we need to find out what is the System Default locale. For such purpose, we use GetSystemDefaultLocaleName function. Once we get the system default locale name, then we set the default locale of our process using setlocale or _wsetlocale function.
Before we call MultiByteToWideChar or WideCharToMultiByte function to convert to or from codepage, we have to set the default locale of our process (or thread), otherwise, we have to explicitly provide codepage identifiers if such conversion is to be successful.
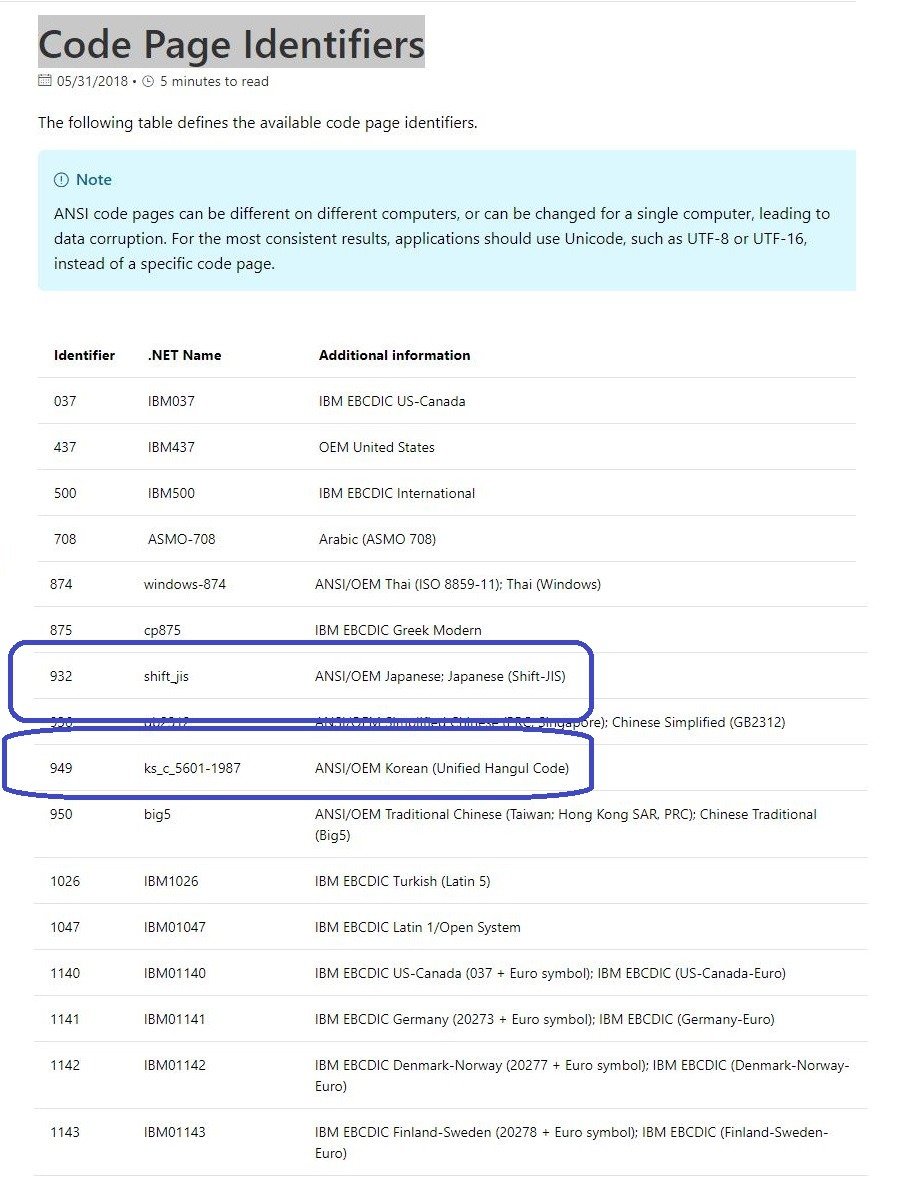
7. For example, if we want to convert codepaged Korean text to UCS2 encoding, we use MultiByteToWideChar function, because codepage encoding is of the Multibyte encoding system and UCS2 is in Wide Character encoding. Since codepage identifier for Korean is 949, we can call
MultiByteToWideChar(949, ...,), where 949 is the codepage identifier for Korean, the codepage identifier for the source of the conversion. The target of this conversion is always in the Wide Character encoding or UCS2 on Windows. So we do not need to concern about the codepage of the target in the call to MultiByteToWideChar function. Note that codepage identifiers are used for Multibyte strings.
8. If we want to convert UCS2 to codepaged Korean, then we use WideCharToMultiByte function, because the source of this conversion is in the Wide Character encoding, and the target is in the Multibyte encoding (such as codepage and UTF7/UTF8), since the codepage identifier for Korean is 949, we can call
WideCharToMultiByte(949, ...), where 949 is the codepage identifier for Korean, the codepage identifier for the target of the conversion. The source of this conversion is always in the Wide Character encoding or UCS2 on Windows. Again the codepage identifier is used for Multibyte strings.
9. I happen to use codepage 949 (or Korean) on my machine. If I hardcode Korean codepage in my program, it will fail on the machines where the default codepage is not 949 (or Korean). Instead, I query the system and find out the default system locale using GetDefaultSystemLocaleName() function, and set this locale to my program using setlocale() function such that it can work on other machines whose system locale is different from that of my machine.
1. Install Precompiled Hunspell Library on Windows
Download Precompiled Hunspell library for Visual Studio 2015 and 2017.
Download Dictionaries for Hunspell Library



How to Implement Spell Checker with Hunspell